
OpenAIの「GPT-4o」は人間並みのレスポンスが可能な映像認識とVoice Modeを搭載!
音声・テキスト・映像に特化したend-to-endモデル
OpenAIは、最新モデル「GPT-4o」(o は「omni」の頭文字)をリリースしました。
全ユーザー(ChatGPT Freeを含む)を対象に、モデル展開を既に開始していると伝えています。
また、今回の目玉である「Voice Mode」については、今後数週間のうちに、ChatGPT Plus(有料)のアルファ版から使用可能になると伝えています。
(Update 2024/6/26)
OpenAIは、Voice Modeのリリース予定時期を、今秋まで延長しました。
人間並みの視覚と会話能力
GPT-4oは、音声と映像の処理能力が強化されています。
- 人間並みの会話レスポンス
- 会話を「被せる」ことができる
- 感情豊かな音声表現ができる
- 静止画・動画を見ながら状況説明ができる
これらのUXは、音声・テキスト・映像向けに訓練された「end-to-endモデル」が基盤となっています。
(コラム)end-to-end モデルとは?
GPT-4oの特徴について、OpenAIは以下のように述べています。
With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
引用元: https://openai.com/index/hello-gpt-4o/
「end-to-end」モデルとは、簡単に説明すると「必要な解析能力を1つに集約したモデル」を指します。
分かり易くするため、ここでは音声データ単体を例に考えてみます。
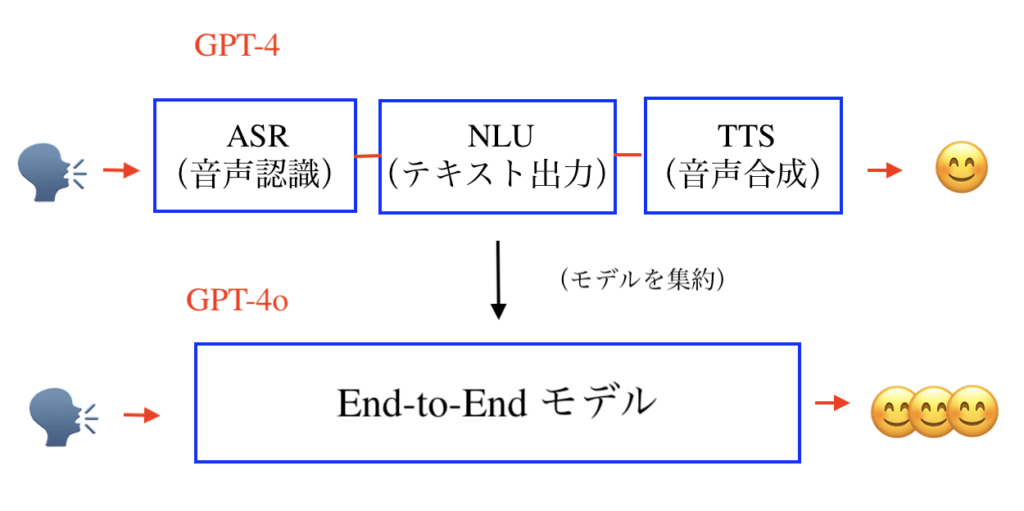
GPT-4では、ASR(音声のテキスト変換)、NLU(テキスト出力)、TTS(テキストの音声変換)の3モデルを使用して、音声処理の解析精度を保っていました。
しかし、複数モデルを使用することは、以下のようなデメリットがあります。
- 全てのモデル処理が完了するまで、時間がかかってしまう(= 入力と出力に時間差が生じる)
- 各モデルのデータ処理過程で、情報が少しずつ失われる(これについて、OpenAIは「音調、複数の話者、背景音の直接観察、そして笑い声、歌、感情の表現が難しくなる」と述べている)
- 各モデルの相性が悪いと、良い出力が生まれない(= 個々のモデル性能を追い求めてもダメ)
この問題点を解消するために考案されたモデルが「End-to-End」、つまり間に挟むモデルを取り除くという手法です。
OpenAIは、この手法を音声・テキスト・映像に適用したことになります。
一体、どのようにモデルを訓練したんでしょうか・・。
GPT-4o が提供する最新UX
サイトで紹介されている動画(一部抜粋)を基に、GPT-4oが提供するUXを纏めました。
1. 映像の説明
静止画だけでなく、streaming中の動画についても、内容を説明することができます。
- セルフィーを見て、表情や感情を言い当てる
- 人物の名前と外見を覚え、会話中も名前で呼びかける
- 走ってくるタクシーを見て、「もうすぐ、タクシーがあなたの前を通りそうです」と伝える
- streaming中の動画の、少し前の内容を言い当てる

2. 会議に参加する
多人数の議論に加わることができます。
- 参加者の1人として意見を言う
- 内容をリアルタイムで要約する
3. 教師になる
分からない問題を映像で示し、「答えは言わずに、解き方のヒントを順に教えて欲しい」と言えば、tutorになってくれます。
4. 歌う
多彩な歌唱表現が可能です。
- 子守唄
- 2つのGPT-4oで交互に歌う、ハーモニーを奏でる
- 「もう少し、高い声で」「もう少し早く」
- 「もっとドラマティックに」
5. 電話代行
デモ動画では、カスタマーサービスに扮したGPT-4oと、電話代行するGPT-4oの掛け合いが映っています。
見た限りでは、実際の電話でも問題なく対応できる会話レベルです。
6. 読み上げ速度の変更
以下のように、細かく指定することができます。
- 「もっと早く喋って」
- 「ちょっと遅いかな、もう少し早く」
- 「それだと早すぎる、その中間ぐらいで」
7. 翻訳する
GPT-4oが仲介役となって、会話をリアルタイム翻訳します。
8. 感情表現
Voice Modeの音声表現は、非常に豊かです。
映像の内容、話者の抑揚、話の内容に合わせて、喋り方を細かくアレンジすることができます。
まとめ
GPT-4oは、音声と映像の処理能力が強化されたOpenAIの最新モデルです。Voice Modeによる音声インタラクションと最新の映像認識能力により、業務効率化や生産性向上が期待できます。
関連記事はこちら //

